An operator types "silver van at the loading bay" into a search box. The job of Mikshi Search is to take that phrase, match it against the deployment's footage, and return — in well under a second — the few seconds across all the cameras that actually correspond to what the operator meant. Not the file. The seconds.
Most "video search" systems can't do this. They turn each video into one vector and search across those, so the answer is always a file, never a moment. That works for short clips. It doesn't work for CCTV, where one camera makes twelve hours a day and the part that matters is thirty seconds long. Pointing at the file just sends the operator back to scrubbing.
So Mikshi Search makes a different set of choices.
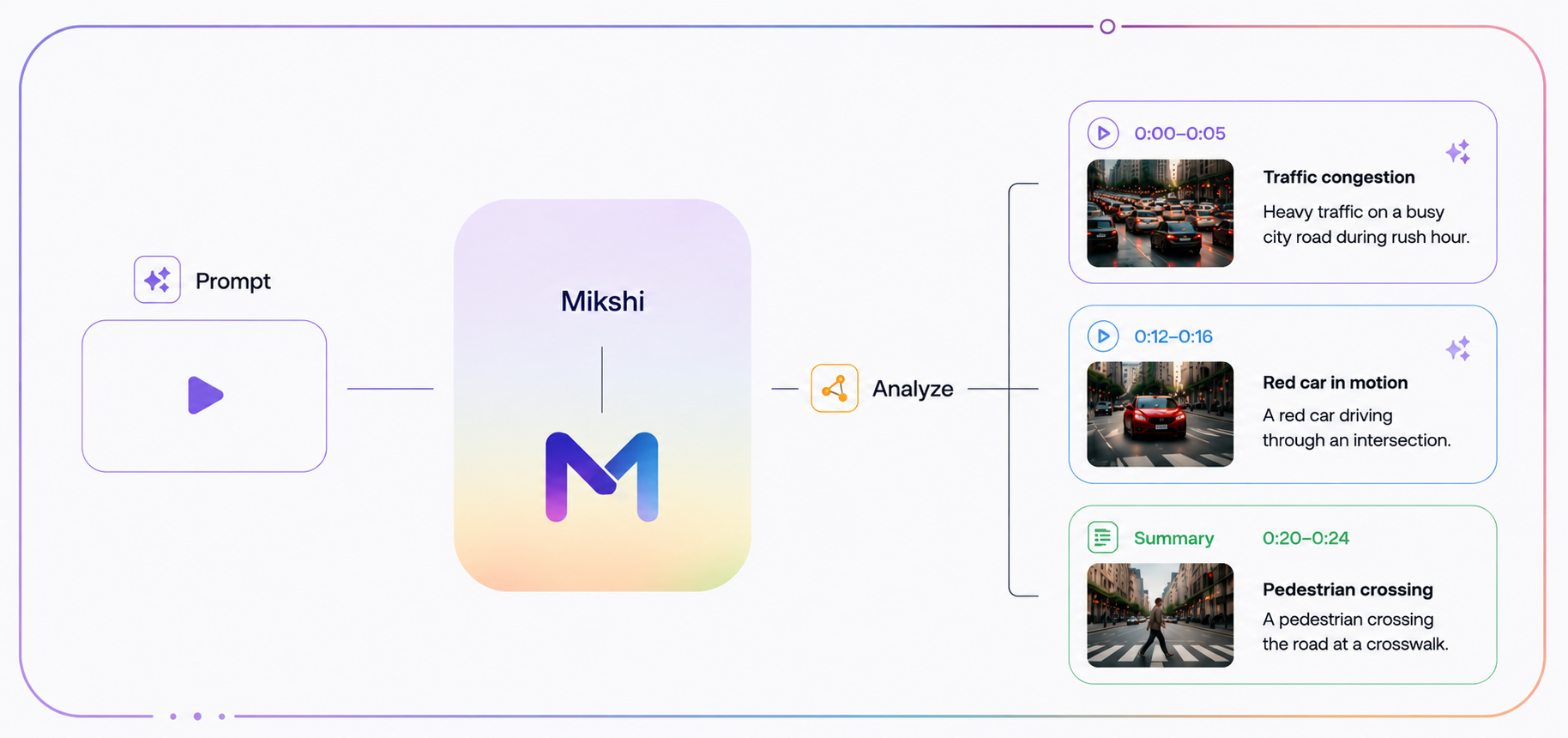
We index clips, not videos
When a new video arrives, the first thing the system does is cut it — but not on a fixed clock. Sliding windows cut straight through the middle of what's happening and give the encoder messy chunks to embed. Instead, we detect natural scene boundaries in the footage and cut there. Quiet stretches collapse into a few wide chunks; busier moments get cut more finely. Each chunk is padded slightly past its edges so the encoder sees a little context, not just the cut.
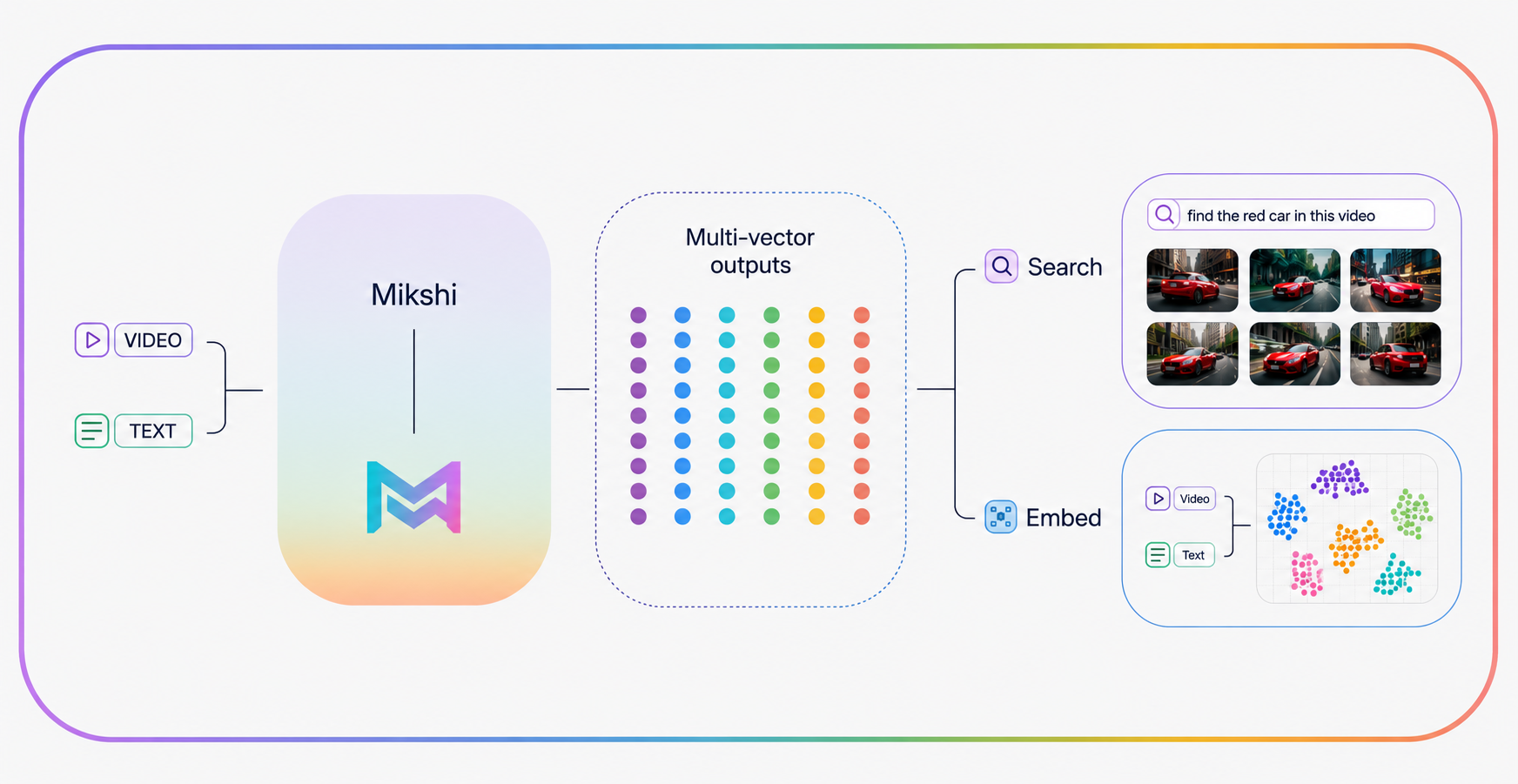
Each chunk goes through the video encoder once and comes out as a single embedding. That embedding, plus the seconds it spans, becomes one row in the index. The thing you index is the thing you retrieve — index files, get back files; index scenes, get back scenes.
Text and video share one space
The operator types in English. The footage is pixels. For search to mean anything, the two have to meet somewhere.
We use one embedding family for both sides. The text the operator types and the clips the encoder watched land in the same space, and the search engine treats them as points — the only question it answers is which clip points sit closest to the query point. That makes the search path very small: encode the query, find the nearest clips, return them. There's no language model in the middle trying to interpret the query. The encoder placed everything in the space at ingest, and search is just geometry from there.
Scope is part of the query
If every query searched the entire archive, the system would slow as soon as a deployment grew. A real deployment has hundreds of cameras and millions of indexed clips. The operator almost never wants all of them — they want this camera, or this collection, or the last four hours.
So scope is resolved first. The request names a set of videos, a collection, or a single camera, and an optional time filter trims it further. The search then runs only over the clips inside that scope — not as a post-filter on the results, but as the actual slice of the index the search reads from. A query that names three cameras searches three cameras' worth of clips, even when the rest of the archive has grown to a year. The archive grows; one query's workload doesn't.
Adjacent clips are the enemy of top-K
A plain nearest-neighbour pass returns a list ranked by similarity. It is rarely a useful list. One event lasts fifteen seconds, which means it produces three or four clips that look almost identical to each other and to the query that matched. Ask for the top five, get the same event five times — same camera, two of them literally next to each other.
So before returning, we run a quick second pass: compare the candidates to each other, group the ones that are too similar, and keep only the best one or two from each group. If that leaves us short of top-K, we top up from the original ranking. What the operator sees is a top-K of different moments, not the same moment in five takes. The step costs almost nothing because it runs over the small candidate set the search already narrowed. The alternative — five near-identical results at the top of every list — is the kind of thing operators stop trusting very quickly.
The same embeddings draw a map
The embeddings the search endpoint queries are the same ones a visualization endpoint can plot. Given a set of videos, the system projects every clip embedding for them down to two dimensions and arranges them as a layout. Clusters of points mean clusters of similar footage. An operator can read the structure of a day of feeds visually — see what repeats, what's anomalous, where things group — without typing a query at all. There's no second model and no second index. The map comes free with the search.
Where the speed comes from
It isn't a tuning win. The heavy work just doesn't happen at query time.
When a video first arrives, the system cuts it into scenes and runs each scene through the encoder once. After that, the clips are just vectors and metadata, and they don't get touched again. A query becomes its own vector through a single encoding call, joins the scoped slice of the index, gets compared to its neighbours, gets thinned for duplicates, and comes back. The video encoder never runs on a query. The only real costs are the text embedding and the nearest-neighbour lookup, and both are bounded by the encoder and the index — not by the size of the archive.
Two things follow from that. A query against a long-running deployment is roughly as fast as a query against a fresh one. And every result comes back grounded in the exact seconds it represents, so a player can jump straight to them.
In one line
Most "video search" is really file search with a video encoder bolted on. It tells you which file the answer is in and makes you find the seconds yourself. That works for a library of curated clips and fails for CCTV, where the file is twelve hours and the seconds are the whole point.
Mikshi Search inverts that. We cut footage into scenes, index the scenes, search the scenes, and return the scenes. Text and video share one space, so search is just nearest-neighbour. Scope is resolved before the search runs, so the index never pays for cameras nobody asked about. Near-duplicates get thinned before they reach the operator, so the top of the list is a list of moments, not five takes on one. None of these are tricks — they fall out of committing, at the indexing level, to seconds instead of hours.