A video-language model is the expensive part of any video intelligence stack. Running one over an hour of footage to answer "what happened around the loading bay this afternoon?" is computationally absurd and, worse, the answer is ungrounded: a single forward pass over thousands of frames cannot give you something it can defend with timestamps. The model that sees too much at once tends to hallucinate, and the model that sees too little misses the moment.
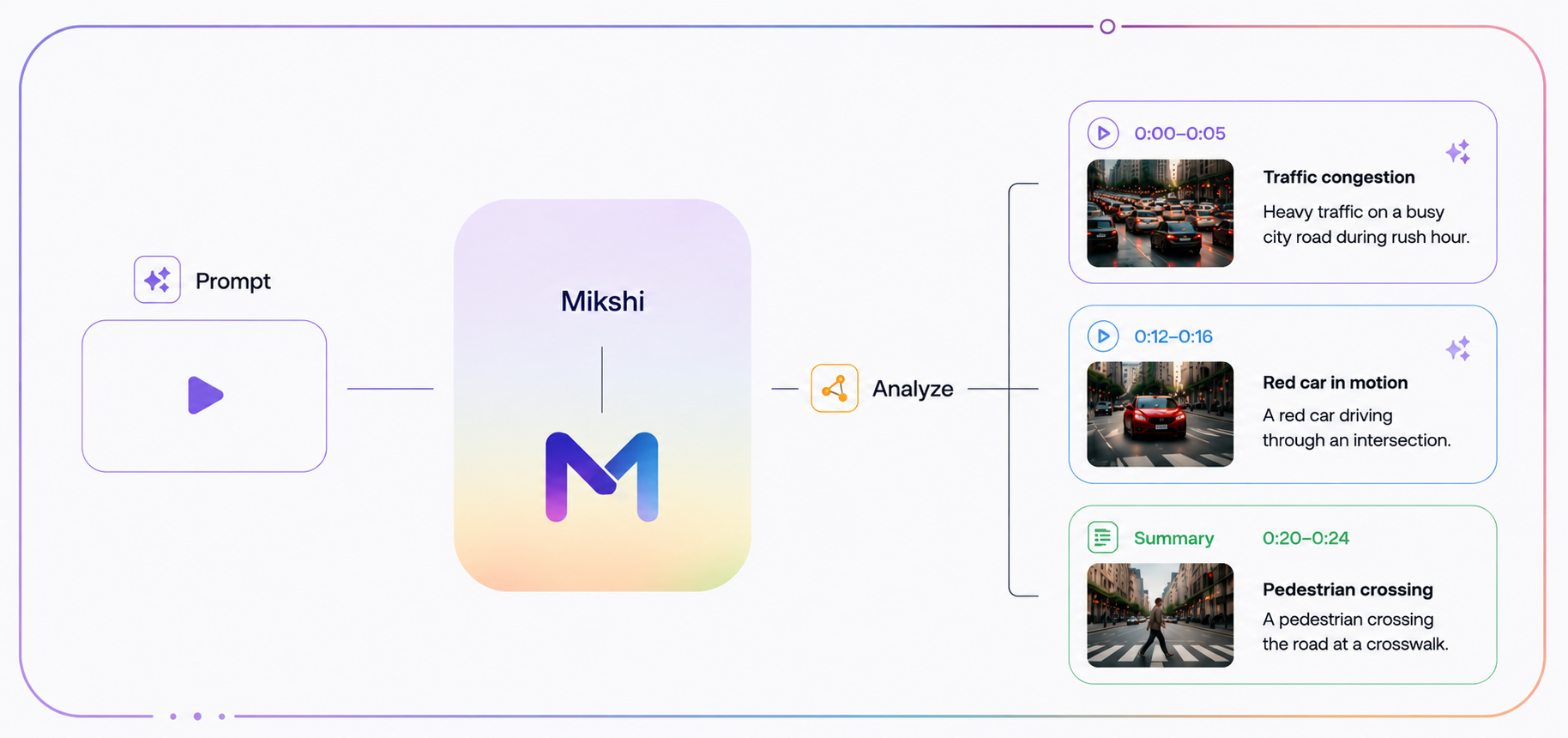
This is the failure mode we built Mikshi Analyze around. The model itself is a video-language model that can describe what it sees. But the system around it — the part that turns "what happened in this video" into "here are the four collisions, here are the timestamps, here are the actors involved, and here is the seven-second clip that grounds each one" — is a retrieval layer built on top of the model's own structured output. The video is processed once. Every subsequent question is answered from the index.
The Premise
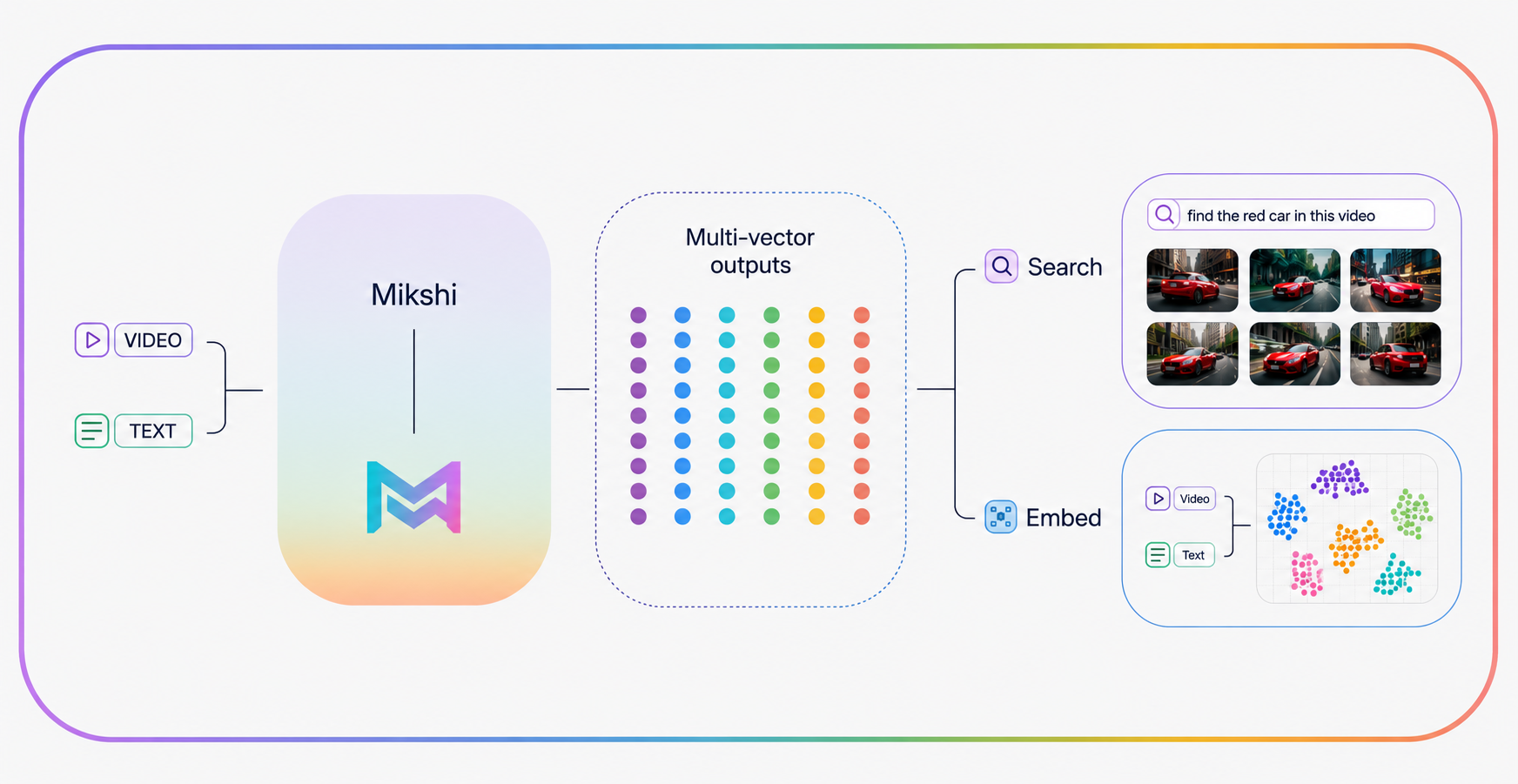
A long video, after Mikshi Analyze has processed it, is not raw pixels. It is a structured artifact — a description of the video that records every event, every actor, the relationships between them, and the time at which each happened. The model has already done the hard sensory work. What remains is to make that artifact queryable, at any granularity an operator can ask for, in milliseconds, without firing the VLM again.
The naive options both fail in their own way. Feeding the full artifact to a language model on every question works for short videos and breaks immediately as length grows; latency, cost, and context-window degradation all bite. Indexing the artifact and running plain semantic search is what most "chat with your data" systems do, and it has two well-known holes: it misses queries that hinge on a specific term an operator typed verbatim, and the top of its ranked list is noisy enough that the answering model often reasons over the "almost right" evidence rather than the right evidence.
Mikshi Analyze's retrieval layer is shaped around closing those two holes.
What Gets Indexed
The corpus is not the raw video. It is the structured output Mikshi Analyze produced when it watched the video — a per-event description that captures the actors, the actions, the context, and the time. Each event becomes a unit of evidence in the index, alongside a video-level summary. Timestamps travel with the evidence, so every answer can point back at when.
Two things matter about this representation. First, the text the retriever sees has already been distilled by the VLM — it is dense with what an operator might actually query, not a transcript of pixel-level noise. Second, the structured fields the model emitted — actors, severities, labels — are preserved alongside the text, which lets the retriever scope its work before semantic matching ever runs.
Two Retrieval Signals, Not One
Plain semantic similarity is the default tool for this kind of system, and it is not enough on its own. Embeddings smooth language — that is what makes them useful for paraphrase, and also what makes them quietly fail when the operator types a specific token they want to match literally: a vehicle type, a location label, a partial identifier from the footage.
Mikshi Analyze runs two retrieval signals over the same index. One is the semantic signal, which catches paraphrase and captures the meaning of an operator's question even when no word in the question appears in the underlying evidence. The other is a lexical signal, which keeps the system honest when the question contains a term the operator clearly meant verbatim. The two signals are fused before ranking, so a single query reaches the right evidence whether it was phrased semantically or specifically.
We did not start with this combination. We added the lexical signal after watching pure semantic search miss queries where the operator was explicitly invoking a token from the footage. Semantic search treats all token information as semantically interchangeable; lexical search does not. For a system whose users phrase questions in operationally specific language, that channel pulls real weight.
Reranking, Because Top-K Is Not the Answer
A retrieval pass gives a clean candidate set. It does not, on its own, give a clean ranking of that set. The closest result in embedding space is not always the one that best answers the question — it is the one closest in a related but weaker sense.
So we add a second pass. Each candidate is rescored against the query with a model that considers the two jointly, rather than judging them by their independent representations. This second pass is the difference between the answering model reasoning over the right evidence and the almost right evidence, and it only runs over the small set the first pass already narrowed, so the precision gain comes cheaply.
Conversational Continuity Without Polluting Retrieval
Operators ask follow-up questions. "What was that vehicle doing?" is a natural turn three of a conversation.
The standard fix is to dump chat history into the query, which works against retrieval rather than for it. So we instead rewrite the current turn into a standalone form using the prior context, and that rewritten query is what reaches the retriever. Chat history shapes the question — it does not contaminate the retrieval signal.
What This Architecture Actually Buys
For an operator, the experience is that questions about long video feel less like prompting a language model and more like searching a structured artifact:
- Answers return in well under the time it would take the VLM to re-watch the video, because it never re-watches it.
- Every answer carries the timestamps it was grounded in.
- Term-specific queries reach the right evidence, because the lexical signal is there to catch what the semantic signal would have over-smoothed.
- The top of the candidate list is governed by a model that sees the query and the evidence together.
- Follow-up questions work, and they do not poison the retrieval signal underneath.
For the system, the architecture is what makes the VLM never run at query time. Mikshi Analyze does its expensive work once, when the video is processed. The retrieval layer takes that work apart and answers questions out of it. The VLM produces evidence; it does not retrieve it.
This split — heavy model up front, indexed structure underneath, hybrid retrieval and a precision pass on top — is what lets the system scale from one video to thousands of hours of video without per-query cost growing with the size of the archive.
Why It Matters
A lot of "video chat" products work the way early "chat with your PDF" products did: feed everything to the model, hope it answers, pay for it on every turn. That works in a demo. It does not work when the video is long, the questions are operationally specific, and the answer has to be defensible.
Mikshi Analyze is built for the second regime. The video is too long to re-watch on every query; the questions span both semantic and literal modes; the answers have to point at evidence. So the system distills the video once into structured evidence, indexes that evidence with both a semantic and a lexical signal, sharpens the top of the ranked list with a precision pass, and lets the language model do what it is good at — synthesizing what is already grounded in front of it.